计量器具识别编码编制进程
2018年6月7日,《计量器具识别编码》发布。
2019年1月1日,《计量器具识别编码》实施。
计量器具识别编码造价信息
主要起草单位:济南大陆机电股份有限公司、山东省标准化研究院、中国电力科学研究院有限公司、青岛市计量技术研究院、日照山川电子信息技术有限公司、山东省计量科学研究院、中国物品编码中心、中电装备山东电子有限公司、海安县综合检验检测中心。
主要起草人:曹瑞基、荆书典、郑安刚、李玉全、张密、唐彪、李宜鹏、李凯迪、苏冠群、张旭、刘继义、傅尔权、刘保会、邹亚雄、彭楚宁、刘兴奇。 2100433B
计量器具识别编码编制进程常见问题
-
对绝对测量来说,要求计量器具的测量范围要大于被测量的量的大小,但不要相差太大。因为用测量范围大的计量器具测量小型工件,不仅不经济,而且测量精度还难以保证。对比较测量来说,计量器具的示值范围一定要大于被...
-
你是哪个地方的,或者你要查哪个地方的企业的?去企业当地的地级市一级的质量监督局的计量局查,如果没有,就去省一级的质量监督局的计量所查,再没有就去国家的质监局查吧
-
水位计是计量器具。水位计是计量器具,在质量控制系统中,也要作为受控仪表进行相应的检定、检测,并保留相应的质量记录。水位计是自动测定并记录河流、湖泊和灌渠等水体的水位的仪器。按传感器原理分浮子式、跟踪式...
计量器具识别编码编制进程文献

 计量器具如何选择(1)
计量器具如何选择(1)
1、计量器具如何选择 ? 答:计量器具的选择主要决定于计量器具的技术指标和经济指标。 技术指标是指 测量范围和测量误差。经济指标是指价格和测量环境要求。 2、什么是基本尺寸、实际尺寸、极限尺寸 ? 答:基本尺寸是在零件设计时,根据使用要求,通过刚度、强度计算或结构等方 面的考虑,并按标准直径或标准长度圆整所给定的尺寸。 它是计算极限尺寸和极 限偏差的起始尺寸。 实际尺寸是通过测量获得的尺寸。 由于存在测量误差, 所以实际尺寸并非尺寸的 真值。同时由于形状误差等影响,零件同一表面不同部位的实际尺寸是不等的。 极限尺寸是指允许尺寸变化的两个极限值。 其中,较大的一个称为最大极限尺寸, 较小的一个称为最小极限尺寸。 3、配合的概念是什么 ? 答:配合是指基本尺寸相同的、互相结合的孔和轴公差带之间的关系。 4、有几种配合 ? 答:国家标准将配合分为三种类型,即:间隙配合、过盈配合和过渡配合。 (1
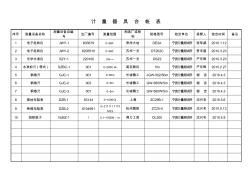 计量器具台帐表
计量器具台帐表
计 量 器 具 台 帐 表 序号 测量设备名称 测量设备自编 号 出厂编号 测量范围 制造厂或商 标 规格型号 检定单位 保管人 检定时间 备注 1 电子经纬仪 JWY-1 603679 0~360。 常州大地 DE2A 宁波计量测试所 张军威 2010.1.12 2 电子经纬仪 JWY-2 6205510 0~360。 苏州一光 DT202C 宁波计量测试所 贺丰盛 2010.3.23 3 光学水准仪 SZY-1 220100 2m~∞ 苏州一光 DSZ2 宁波计量测试所 严东辉 2010.3.23 4 水准标尺(塔式) SZBC-1 001 0~2000 ㎜ 南京顺风 5m 宁波计量测试所 严东辉 2010.2.27 5 钢卷尺 GJC-1 001 0~50m 长城精工 JGW-502/50m 宁波计量测试所 谢 吉 2010.4.3 6 钢卷尺 GJC-2 003 0~5m
计量器具控制(comtrol of measuring instruments):确定计量器具的性能并签发关于该计量器具法定地位的官方文件。这种控制可包括对该计量器具的下列运作中的一项、两项或三项:型式批准、检定、检验。2100433B
内容
《一种应用于虹膜识别的编码方法及系统》涉及一种应用于虹膜识别的编码方法,包括:步骤1:加载物体的眼睛图片,获取虹膜图像;步骤2:对所述虹膜图像进行分割,根据具体需求提取出需要处理的区域得到待处理图像;步骤3:对待处理图像进行标准的二维傅里叶变换,使待处理图像从空间域转换为频率域,得到待处理数据;步骤4:加载最优参数集,基于最优参数集对待处理数据进行滤波操作,得到相位信号和幅值信号;步骤5:将相位信号和幅值信号进行编码为计算机数据结构,得到对应的生物编码。本发明增加分类器的置信水平从而提高匹配过程的稳定性;利用一个二值分类器来判断两个编码是否源于相同的人眼,该二值分类器从离线的相位编码得到多级置信值。
这里主要介绍线性编码有关内容
线性编码
术语代数编码理论表示编码原理的子领域,其编码性质以代数术语表示,然后进一步研究 。
代数编码理论基本上分为两大类代码:
线性分组码
卷积码
它分析一个编码的以下三个特性-主要是:
码字长度
有效代码字总数
两个有效代码字之间的最小距离,主要使用汉明距离,有时也使用其他距离像Lee距离。
线性分组码
线性分组码具有的特性的线性度,即,任何两个码字的总和也是一个编码字,并且它们被应用到组的源比特中,因此称为线性分组码。有分组码不是线性的,但是很难证明编码是没有这个属性的编码。
线性分组码由其符号字母(例如,二进制或三元)和参数(n,m,
n是码字的长度,以符号表示,
m是将一次用于编码的源符号的数量,
有许多类型的线性分组码,如循环码(如汉明码)、重复代码、奇偶校验码、多项式编码(例如BCH码)、里德 - 所罗门编码、代数几何编码、里德 - 穆勒编码、完美编码。
编码原理使用N维球体模型。例如,可以在桌面上或三维中将多少便士包装成圆圈,可以将多少个弹珠包装在一个球面上。其他注意事项输入编码的选择。例如,六边形包装成矩形框的约束将在角落留下空的空间。随着尺寸越来越大,空白空间的百分比越来越小。但是在某些维度上,包装使用所有空间,这些代码是所谓的“完美”代码。唯一非常重要和有用的完美编码是距离为3汉明码,其参数满足(2 r - 1,2 r - 1 - r,3)和[23,12,7]二进制和[11,6,5 ]三重Golay码。
另一个编码属性是单个码字可能具有的邻居的数量。再次,以便士为例。首先我们把便士打包成矩形网格。每一分钱将有4个邻近的邻居(在距离更远的角落有4个)。在六边形,每一分钱将有6个近邻。当我们增加尺寸时,近邻的数量增加非常快。结果是使接收端选择邻居(因此错误)的噪声的方式也增加。这是分组码以及所有编码的基本限制。可能更难对单个邻居造成错误,但邻居数量可能足够大,因此总错误概率实际上会受到影响。
线性分组码的属性可以应用于很多应用。例如,线性分组码的校正子集合唯一性被用网格成形,是最有名的形状码之一。传感器网络中使用相同的属性进行分布式源代码编码。
卷积码
如果特定的一致监督关系不是在一个码字中实现,而是在个码字中实现,这种码称为卷积码。卷积码可用移位寄存器来实现,这种卷积编码器的输出可看作是输入信息码元序列与编码器响应函数的卷积。能纠正突发错误的哈格伯尔格码也是一种卷积码。在平稳高斯噪声干扰的信道上采用序贯译码方法的卷积码有很好的性能,能用于卫星通信和深空通信。
UTF-8 编码原理
为了统一全世界各国语言文字和专业领域符号(例如数学符号、乐谱符号)的编码,ISO制定了ISO 10646标准,也称为UCS(Universal Character Set)。UCS编码的长度是31位,可以表示231个字符。如果两个字符编码的高位相同,只有低16位不同,则它们属于一个平面(Plane),所以一个平面由216个字符组成。目前常用的大部分字符都位于第一个平面(编码范围是U-00000000~U-0000FFFD),称为BMP(Basic Multilingual Plane)或Plane 0,为了向后兼容,其中编号为0~256的字符和Latin-1相同。UCS编码通常用U-xxxxxxxx这种形式表示,而BMP的编码通常用 U xxxx这种形式表示,其中x是十六进制数字。在ISO制定UCS的同时,另一个由厂商联合组织也在着手制定这样的编码,称为Unicode,后来两家联手制定统一的编码,但各自发布各自的标准文档,所以UCS编码和Unicode码是相同的。
有了字符编码,另一个问题就是这样的编码在计算机中怎么表示。现在已经不可能用一个字节表示一个字符了,最直接的想法就是用四个字节表示一个字符,这种表示方法称为UCS-4或UTF- 32,UTF是Unicode Transformation Format的缩写。一方面这样比较浪费存储空间,由于常用字符都集中在BMP,高位的两个字节通常是0,如果只用ASCII码或Latin-1,高位的三个字节都是0。另一种比较节省存储空间的办法是用两个字节表示一个字符,称为UCS-2或UTF-16,这样只能表示BMP中的字符,但BMP中有一些扩展字符,可以用两个这样的扩展字符表示其它平面的字符,称为Surrogate Pair。无论是UTF-32还是UTF-16都有一个更严重的问题是和C语言不兼容,在C语言中0字节表示字符串结尾,库函数strlen、 strcpy等等都依赖于这一点,如果字符串用UTF-32存储,其中有很多0字节并不表示字符串结尾,这就乱套了。
UNIX之父Ken Thompson提出的UTF-8编码很好地解决了这些问题,现在得到广泛应用。UTF-8具有以下性质:
* 编码为U 0000~U 007F的字符只占一个字节,就是0x00~0x7F,和ASCII码兼容。
* 编码大于U 007F的字符用2~6个字节表示,每个字节的最高位都是1,而ASCII码的最高位都是0,因此非ASCII码字符的表示中不会出现ASCII码字节(也就不会出现0字节)。
* 用于表示非ASCII码字符的多字节序列中,第一个字节的取值范围是0xC0~0xFD,根据它可以判断后面有多少个字节也属于当前字符的编码。后面每个字节的取值范围都是0x80~0xBF,见下面的详细说明。
* UCS定义的所有231个字符都可以用UTF-8编码表示出来。
* UTF-8编码最长6个字节,BMP字符的UTF-8编码最长三个字节。
* 0xFE和0xFF这两个字节在UTF-8编码中不会出现。
具体来说,UTF-8编码有以下几种格式:
U-00000000 – U-0000007F: 0xxxxxxx
U-00000080 – U-000007FF: 110xxxxx 10xxxxxx
U-00000800 – U-0000FFFF: 1110xxxx 10xxxxxx10xxxxxx
U-00010000 – U-001FFFFF: 11110xxx 10xxxxxx10xxxxxx 10xxxxxx
U-00200000 – U-03FFFFFF: 111110xx 10xxxxxx10xxxxxx 10xxxxxx 10xxxxxx
U-04000000 – U-7FFFFFFF: 1111110x 10xxxxxx10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
第一个字节要么最高位是0(ASCII字节),要么最高两位都是1,最高位之后1的个数决定后面有多少个字节也属于当前字符编码,例如111110xx,最高位之后还有四个1,表示后面有四个字节也属于当前字符的编码。后面每个字节的最高两位都是10,可以和第一个字节区分开。这样的设计有利于误码同步,例如在网络传输过程中丢失了几个字节,很容易判断当前字符是不完整的,也很容易找到下一个字符从哪里开始,结果顶多丢掉一两个字符,而不会导致后面的编码解释全部混乱了。上面的格式中标为x的位就是UCS编码,最后一种6字节的格式中x位有31个,可以表示31位的UCS编码,UTF-8就像一列火车,第一个字节是车头,后面每个字节是车厢,其中承载的货物是UCS编码。UTF-8规定承载的UCS编码以大端表示,也就是说第一个字节中的x是UCS编码的高位,后面字节中的x是UCS编码的低位。
例如U 00A9(©字符)的二进制是10101001,编码成UTF-8是11000010 10101001(0xC2 0xA9),但不能编码成11100000 10000010 10101001,UTF-8规定每个字符只能用尽可能少的字节来编码。
计量器具识别编码相关推荐
- 相关百科
- 相关知识
- 相关专栏
- 钻孔成桩设备
- 格栅面积
- 确定最优计算模板的方法和装置
- 新编钣金展开计算模板200例
- 容积率指标计算规则
- 高温(火灾)下植筋式后锚固连接的抗剪机理研究
- 钻井工程全过程工程量清单计价标准
- 电耗定额
- 电力建设工程工期定额
- 电力建设工程调试定额
- 建筑工程快速识图技巧
- 建筑弱电工程施工技术详解
- 建筑弱电工程设计与安装手册
- 小型临时设施
- 造价经验提升篇做报价有技巧
- 材料收入计价
- 园林工程计量与计价园路园桥工程计量与计价
- 有线电视广播系统运行维护规程编制情况和宣贯要点
- 执行新颁公路基本建设概、预算编制办法及定额的体会
- 云南省造价工程师安装计量:除锈、刷油和衬里考试题
- 云南省机关事业单位编制外人员劳动合同书(修改后)
- 云南省公路工程工程量清单计量规范B01-2010
- 云南省公路工程安全生产工程量标准清单编制方法思考
- 择压法检测砌筑砂浆抗压强度技术规程召开编制组会议
- 云南省公路建设项目水土保持方案编制难点分析及建议
- 应急救援预案编制的基本步骤与应急演练工作计划汇编
- 光纤改造进程
- 有关西部县区的工业化进程带来的环境污染和治理问题
- 有关公路工程概预算编制工作中工程量的计算要点分析
- 公路建设项目可行性报告编制存在问题与解决建议
- 公路工程施工项目部安全生产管理内业资料编制归档办法
- 工程造价信息与工程量清单报价编制在建设工程中运用
最新词条
安徽省政采项目管理咨询有限公司
数字景枫科技发展(南京)有限公司
怀化市人民政府电子政务管理办公室
河北省高速公路京德临时筹建处
中石化华东石油工程有限公司工程技术分公司
手持无线POS机
广东合正采购招标有限公司
上海城建信息科技有限公司
甘肃鑫禾国际招标有限公司
烧结金属材料
齿轮计量泵
广州采阳招标代理有限公司河源分公司
高铝碳化硅砖
博洛尼智能科技(青岛)有限公司
烧结刚玉砖
深圳市东海国际招标有限公司
搭建香蕉育苗大棚
SF计量单位
福建省中亿通招标咨询有限公司
泛海三江
威海鼠尾草
广东国咨招标有限公司
Excel 数据处理与分析应用大全
甘肃中泰博瑞工程项目管理咨询有限公司
山东创盈项目管理有限公司
当代建筑大师
广西北缆电缆有限公司
拆边机
大山槟榔
上海地铁维护保障有限公司通号分公司
甘肃中维国际招标有限公司
舌花雏菊
华润燃气(上海)有限公司
湖北鑫宇阳光工程咨询有限公司
GB8163标准无缝钢管
中国石油炼化工程建设项目部
韶关市优采招标代理有限公司
莎草目
建设部关于开展城市规划动态监测工作的通知
电梯平层准确度
广州利好来电气有限公司
苏州弘创招投标代理有限公司