哈夫曼算法
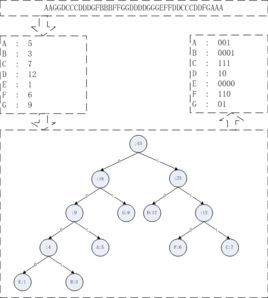
哈夫曼树是一种树形结构,用哈夫曼树的方法解编程题的算法就叫做哈夫曼算法。树并不是指植物,而是一种数据结构,因为其存放方式颇有点象一棵树有树叉因而称为树。 最简哈夫曼树是由德国数学家冯.哈夫曼 发现的,此树的特点就是引出的路程最短。 概念理解:1.路径 从树中一个节点到另一个节点之间的分支构成这两个节点之间的路径。2.路径长度 路径上的分支数目称作路径长度。
哈夫曼算法基本信息
| 中文名称 | 哈夫曼树 | 结构 | 树形结构 |
|---|---|---|---|
| 算法 | 哈夫曼算法 | 类别 | 数据结构 |
| 发明者 | 冯·哈夫曼 | 发明国家 | 德国 |
用C语言最简单的哈夫曼算法实现
#include <stdio.h>
#include <conio.h>
struct BinaryTree
{
long data;
int lchild,rchild;
};
//定义一个二叉树结构
void sort(struct BinaryTree cc[],int l,int r);
void xx(long kk,struct BinaryTree cc[]);
void zx(long kk,struct BinaryTree cc[]);
void hx(long kk,struct BinaryTree cc[]);
//对函数的声明
main(void)
{
struct BinaryTree Woods[101];
long i,j,n,xs,k;
scanf("%d",&n);
for ( i=1; i<=n; ++i)
{
scanf("%d",&Woods.data);
Woods.lchild=0;
Woods.rchild=0;
} //依次读入权值
k=n;
xs=1;
--n;
while (k>1)
{
sort(Woods,xs,n+1);
Woods[n+2].data=Woods[xs].data+Woods[xs+1].data; //将根结点权值为左子树也右子树权值之和
Woods[n+2].lchild=xs; //对左子树和右子树的设置
Woods[n+2].rchild=xs+1;
++n;
xs=xs+2;
--k;
} //哈夫曼算法
printf("%s","preorder:");
xx(n+1,Woods);
printf("\n%s","inorder:");
zx(n+1,Woods);
printf("\n%s","postorder");
hx(n+1,Woods);
printf("\n"); //输出先序,中序,后序序列
getch();
}
//快速排序
void sort(struct BinaryTree cc[],int l,int r)
{
long x,y;
int i,j,rc,lc;
i=l;
j=r;
x=cc[(l+r)/2].data;
if (r<l)
return;
do
{
while(cc.data<x)
++i;
while(x<cc[j].data)
--j;
if (i<j)
{
y=cc.data;
rc=cc.rchild;
lc=cc.lchild;
cc.data=cc[j].data;
cc.lchild=cc[j].lchild;
cc.rchild=cc[j].rchild;
cc[j].data=y;
cc[j].lchild=lc;
cc[j].rchild=rc;
++i;
--j;
}
}
while(i>j);
if (i<r)
sort(cc,i,r);
if (j>l)
sort(cc,l,j);
}
//先序序列
void xx(long kk,struct BinaryTree cc[])
{
if (cc[kk].data!=0)
{
printf("%d%c",cc[kk].data,' ');
if (cc[kk].lchild!=0)
xx(cc[kk].lchild,cc);
if (cc[kk].rchild!=0)
xx(cc[kk].rchild,cc);
}
}
//中序序列
void zx(long kk,struct BinaryTree cc[])
{
if (cc[kk].data!=0)
{
if (cc[kk].lchild!=0)
zx(cc[kk].lchild,cc);
printf("%d%c",cc[kk].data,' ');
if (cc[kk].rchild!=0)
zx(cc[kk].rchild,cc);
}
}
//后序序列
void hx(long kk,struct BinaryTree cc[])
{
if (cc[kk].data!=0)
{
if (cc[kk].lchild!=0)
hx(cc[kk].lchild,cc);
if (cc[kk].rchild!=0)
hx(cc[kk].rchild,cc);
printf("%d%c",cc[kk].data,' ');
}
}
哈夫曼算法造价信息
1.初始化: 根据给定的n个权值{w1,w2,…wn}构成n棵二叉树的集合F={T1,T2,..,Tn},其中每棵二叉树Ti中只有一个带权wi的根结点,左右子树均空。
2. 找最小树:在F中选择两棵根结点权值最小的树作为左右子树构造一棵新的二叉树,且至新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
3. 删除与加入:在F中删除这两棵树,并将新的二叉树加入F中。
4. 判断:重复前两步(2和3),直到F中只含有一棵树为止。该树即为哈夫曼树
哈夫曼算法常见问题
哈夫曼算法文献

 哈夫曼树编码译码实验报告
哈夫曼树编码译码实验报告
数 据 结 构 课 程 设 计 设计题目: 哈夫曼树编码译码 课题名称 哈夫曼树编码译码 院 系 年级专业 学 号 姓 名 成 绩 课题设计 目的与 设计意义 1、课题设计目的: 在当今信息爆炸时代,如何采用有效的数据压缩技术节省数据文 件的存储空间和计算机网络的传送时间已越来越引起人们的重视, 哈夫曼编码正是一种应用广泛且非常有效的数据压缩技术。哈夫曼 编码是一种编码方式,以哈夫曼树—即最优二叉树,带权路径长度 最小的二叉树,经常应用于数据压缩。哈弗曼编码使用一张特殊的 编码表将源字符(例如某文件中的一个符号)进行编码。这张编码 表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立 起来的。 2、课题设计意义: 哈夫曼编码的应用很广泛,利用哈夫曼树求得的用于通信的二进 制编码称为哈夫曼编码。树中从根到每个叶子都有一条路径,对路 径上的各分支约定:指向左子树的分支表示“ 0”码,指向
 哈夫曼编码译码系统实验报告,数据结构课程设计
哈夫曼编码译码系统实验报告,数据结构课程设计
安徽大学 数据结构课程设计报告 项目名称:哈弗曼编 /译码系统的设计 与实现 姓名:鉏飞祥 学号: E21414018 专业:软件工程 完成日期 2016/7/4 计算机科学与技术学院 1 1 . 需求分析 1.1 问题描述 ? 问题描述:利用哈夫曼编码进行通信可以大大提高信道利用率, 缩短信息传输时间, 降低传输成本。 但是,这要求在发送端通过一个编码 系统对待传数据预先编码,在接收端将传来的数据进行译码(解码) 。对 于双工信道(即可以双向传输信息的信道) ,每端都需要一个完整的编 / 译码系统。试为这样的信息收发站设计一个哈夫曼编译码系统。 1.2 基本要求 (1) 输入的形式和输入值的范围; (2) 输出的形式; (3) 程序所能达到的功能。 1.基本要求 (1)初始化( Initialzation )。从数据文件 DataFile.data 中读入字符及 每个字符的权
从上述算法中可以看出,F实际上是森林,该算法的思想是不断地进行森林F中的二叉树的"合并",最终得到哈夫曼树。
在构造哈夫曼树时,可以设置一个结构数组HuffNode保存哈夫曼树中各结点的信息,根据二叉树的性质可知,具有n个叶子结点的哈夫曼树共有2n-1个结点,所以数组HuffNode的大小设置为2n-1,数组元素的结构形式如下:
weight | lchild | rchild | parent |
其中,weight域保存结点的权值,lchild和rchild域分别保存该结点的左、右孩子结点在数组HuffNode中的序号,从而建立起结点之间的关系。为了判定一个结点是否已加入到要建立的哈夫曼树中,可通过parent域的值来确定。初始时parent的值为-1,当结点加入到树中时,该结点parent的值为其双亲结点在数组HuffNode中的序号,就不会是-1了。
构造哈夫曼树时,首先将由n个字符形成的n个叶结点存放到数组HuffNode的前n个分量中,然后根据前面介绍的哈夫曼方法的基本思想,不断将两个小子树合并为一个较大的子树,每次构成的新子树的根结点顺序放到HuffNode数组中的前n个分量的后面。
下面给出哈夫曼树的构造算法。
const maxvalue= 10000; {定义最大权值}
maxleat=30; {定义哈夫曼树中叶子结点个数}
maxnode=maxleaf*2-1;
type HnodeType=record
weight: integer;
parent: integer;
lchild: integer;
rchild: integer;
end;
HuffArr:array[0..maxnode] of HnodeType;
var ……
procedure CreatHaffmanTree(var HuffNode: HuffArr); {哈夫曼树的构造算法}
var i,j,m1,m2,x1,x2,n: integer;
begin
readln(n); {输入叶子结点个数}
for i:=0 to 2*n-1 do {数组HuffNode[ ]初始化}
begin
HuffNode.weight=0;
HuffNode.parent=-1;
HuffNode.lchild=-1;
HuffNode.rchild=-1;
end;
for i:=0 to n-1 do read(HuffNode.weight); {输入n个叶子结点的权值}
for i:=0 to n-1 do {构造哈夫曼树}
begin
m1:=MAXVALUE; m2:=MAXVALUE;
x1:=0; x2:=0;
for j:=0 to n i-1 do
if (HuffNode[j].weight
begin m2:=m1; x2:=x1;
m1:=HuffNode[j].weight; x1:=j;
end
else if (HuffNode[j].weight
begin m2:=HuffNode[j].weight; x2:=j; end;
{将找出的两棵子树合并为一棵子树}
HuffNode[x1].parent:=n i; HuffNode[x2].parent:=n i;
HuffNode[n i].weight:= HuffNode[x1].weight HuffNode[x2].weight;
HuffNode[n i].lchild:=x1; HuffNode[n i].rchild:=x2;
end;
end;
哈夫节是管道堵漏器。哈夫节和承插哈夫节是管路抢修装置,承插哈夫节是对两管子连接处的承口处漏水进行抢修的装置,哈夫节是对除承口以外的部分进行抢修的装置,该装置结构简单只有两件本体和两件橡胶垫组成的,安装方便,只将两本体对合在漏水处拧紧螺母即可完成对管道的抢修,用该装置既可节省停水的时间,又可降低抢修成本 。
在这一部分,我们就来描述源于Dr Kalman 的卡尔曼滤波器。下面的描述,会涉及一些基本的概念知识,包括概率(Probability),随机变量(Random Variable),高斯或正态分配(Gaussian Distribution)还有State-space Model等等。但对于卡尔曼滤波器的详细证明,这里不能一一描述。
首先,我们先要引入一个离散控制过程的系统。该系统可用一个线性随机微分方程(Linear Stochastic Difference equation)来描述:
X(k)=A X(k-1)+B U(k)+W(k)
再加上系统的测量值:
Z(k)=H X(k)+V(k)
上两式子中,X(k)是k时刻的系统状态,U(k)是k时刻对系统的控制量。A和B是系统参数,对于多模型系统,他们为矩阵。Z(k)是k时刻的测量值,H是测量系统的参数,对于多测量系统,H为矩阵。W(k)和V(k)分别表示过程和测量的噪声。他们被假设成高斯白噪声(White Gaussian Noise),他们的covariance 分别是Q,R(这里我们假设他们不随系统状态变化而变化)。
对于满足上面的条件(线性随机微分系统,过程和测量都是高斯白噪声),卡尔曼滤波器是最优的信息处理器。下面我们来用他们结合他们的covariances 来估算系统的最优化输出(类似上一节那个温度的例子)。
首先我们要利用系统的过程模型,来预测下一状态的系统。假设现在的系统状态是k,根据系统的模型,可以基于系统的上一状态而预测出现在状态:
X(k|k-1)=A X(k-1|k-1)+B U(k) ……….. (1)
式(1)中,X(k|k-1)是利用上一状态预测的结果,X(k-1|k-1)是上一状态最优的结果,U(k)为现在状态的控制量,如果没有控制量,它可以为0。
到现在为止,我们的系统结果已经更新了,可是,对应于X(k|k-1)的covariance还没更新。我们用P表示covariance:
P(k|k-1)=A P(k-1|k-1) A'+Q ……… (2)
式(2)中,P(k|k-1)是X(k|k-1)对应的covariance,P(k-1|k-1)是X(k-1|k-1)对应的covariance,A'表示A的转置矩阵,Q是系统过程的covariance。式子1,2就是卡尔曼滤波器5个公式当中的前两个,也就是对系统的预测。
现在我们有了现在状态的预测结果,然后我们再收集现在状态的测量值。结合预测值和测量值,我们可以得到现在状态(k)的最优化估算值X(k|k):
X(k|k)= X(k|k-1)+Kg(k) (Z(k)-H X(k|k-1)) ……… (3)
其中Kg为卡尔曼增益(Kalman Gain):
Kg(k)= P(k|k-1) H' / (H P(k|k-1) H' + R) ……… (4)
到现在为止,我们已经得到了k状态下最优的估算值X(k|k)。但是为了要令卡尔曼滤波器不断的运行下去直到系统过程结束,我们还要更新k状态下X(k|k)的covariance:
P(k|k)=(I-Kg(k) H)P(k|k-1) ……… (5)
其中I 为1的矩阵,对于单模型单测量,I=1。当系统进入k+1状态时,P(k|k)就是式子(2)的P(k-1|k-1)。这样,算法就可以自回归的运算下去。
卡尔曼滤波器的原理基本描述了,式子1,2,3,4和5就是他的5 个基本公式。根据这5个公式,可以很容易的实现计算机的程序。
哈夫曼算法相关推荐
- 相关百科
- 相关知识
- 相关专栏
- 蒸汽凝结水回收装置
- 斯泰迪
- 矮蒿
- 红外线摄温仪
- 叶子结点
- C++数据结构原理与经典问题求解
- 蒸汽冷凝水回收机
- 凤凰草
- 凝结水回收设备
- 合成氨生产技术问答
- 热力入口
- 存储系统
- 数据结构(C++版)学习辅导与实验指导(第2版)
- 高级数据结构
- 线索化
- 石松科
- 圆形钢筋混凝土截面大偏压构件正截面承载力的简算法
- 应用于机电暂态仿真的直流输电系统控制特性算法
- 应用于分布式光纤拉曼温度传感器的温度补偿电路
- 中国石化与巴斯夫合资化工生产基地扩建项目获得批准
- 抑制TCR隔离变压器磁通饱和控制算法与应用
- 改进遗传算法在浅埋隧道施工倾斜地表沉降预测中应用
- 广州白云机场铂尔曼大酒店消防系统维修保养项目及要求
- 基于BP神经网络改进算法在地铁隧道施工中沉降预测
- 基于Dijkstra算法兰州某区热水管道铺设问题
- 哈大铁路客运专线桥梁、路基沉降变形曲线收敛规律
- 基于GA-BP算法建筑业合作伙伴综合实力评价
- 哈尔滨市墙体材料革新和建筑节能管理办法(94号令)
- 基于RFID技术城市轨道交通列车自动记点算法
- 哈尔滨地区办公建筑夜间机械通风能耗及室内热环境分析
- 哈尔滨市轨道交通一号线太平桥车辆段消防给水系统设计
- 基于GIS哈尔滨网通网络资源管理系统设计与实现
最新词条
安徽省政采项目管理咨询有限公司
数字景枫科技发展(南京)有限公司
怀化市人民政府电子政务管理办公室
河北省高速公路京德临时筹建处
中石化华东石油工程有限公司工程技术分公司
手持无线POS机
广东合正采购招标有限公司
上海城建信息科技有限公司
甘肃鑫禾国际招标有限公司
烧结金属材料
齿轮计量泵
广州采阳招标代理有限公司河源分公司
高铝碳化硅砖
博洛尼智能科技(青岛)有限公司
烧结刚玉砖
深圳市东海国际招标有限公司
搭建香蕉育苗大棚
SF计量单位
福建省中亿通招标咨询有限公司
泛海三江
威海鼠尾草
Excel 数据处理与分析应用大全
广东国咨招标有限公司
甘肃中泰博瑞工程项目管理咨询有限公司
山东创盈项目管理有限公司
当代建筑大师
广西北缆电缆有限公司
拆边机
大山槟榔
上海地铁维护保障有限公司通号分公司
甘肃中维国际招标有限公司
舌花雏菊
湖北鑫宇阳光工程咨询有限公司
GB8163标准无缝钢管
中国石油炼化工程建设项目部
华润燃气(上海)有限公司
韶关市优采招标代理有限公司
莎草目
建设部关于开展城市规划动态监测工作的通知
电梯平层准确度
广州利好来电气有限公司
四川中泽盛世招标代理有限公司