RDS系列螺带式混合机
立式混合机广泛应用于工业生产中各种混合、干燥工艺。该机具有三重混合作用,可以在极度短的时间内获得很好的混合效果。
RDS系列螺带式混合机基本信息
| 中文名 | RDS系列螺带式混合机 | 应 用 | 工业生产中各种混合、干燥工艺 |
|---|---|---|---|
| 特 点 | 出料迅速、彻底、无滞留物 | 优 势 | 极短时间获得很好的混合效果 |
特点
1、底部无支撑,出料迅速、彻底、无滞留物。
2、经特殊设计,设备符合GMP标准要求。
3、混合平缓,不会恶化敏感的原料混合物。
RDS系列螺带式混合机造价信息
RDS系列螺带式混合机常见问题
-
南通克莱尔相当不错、高端品质、由一帮从国外公司脱离出来的一帮人做
-
这个看你要求来选配的,不是越大越好的,金昶泰你倒是可以看看。 卧式螺带混合机由U形容器、螺带搅拌叶片和传动部件组成。螺带分连续式和断开式,螺带叶片一般做成双层或三层,外层螺旋物料从两侧向中央汇...
-
混合机底部出料方式:粉体物料采用气动大开门结构形式,具有卸料快、无残余等优点; 高细度物料或半流体物料采用采用手动蝶阀或者气动蝶阀,手动蝶阀经济适用,气动蝶阀对半流体的密封性好,但造价比手动蝶阀高。在...
RDS系列螺带式混合机文献

 混合机安装方
混合机安装方
- 1 - 混合机安装方案 1、工程概况 本工程为一条完整的氧化球团生产线, 主要工程内容包括: 邯钢第 三原料厂与球团之间的一条原料输入皮带(水平长度约 245 米)和一条 球团矿输出皮带(水平长度约 264米)、精矿配料室、干燥室、高压辊压 室、混合室、造球室、链篦机室、回转窑、环冷机、成品仓、压气站、 主控楼、转运站和通廊及配套辅助设施的土建、结构管、道设备安装。 其中混合室混合机重量较大,总重重约 13吨,安装标高± 3.0 米,位于 混合室一层平台,由于是进口设备,安装精度要求较高需制定科学合理 的施工方案。 2、编制依据 电子版图 188MZ2-8 《现场设备、工业管道焊接工程施工及验收规范》 (GB50236—98) 《起重设备安装工程施工及验收规范》 (GB50248-98) 《机械设备安装工程施工及验收规范》 (GB50231-98) 《50液压吊性能表》 3、混合机
 卧式双螺旋混合机设计
卧式双螺旋混合机设计
前 言 搅拌设备使用历史悠久,大量应用于化工、石化、轻工、医药、食品、采矿、冶金等行业中。 搅拌设备可以从各种不同角度进行分类, 如按照搅拌装置的安装形式简单的可分为立式和卧式, 其 中卧式是指搅拌容器轴线与混合机回转轴线都处于水平位置。 本课题在国内外混合机的研究与发展的基础上, 设计了一种新的带有搅拌功能的卧式混合机结 构设计方案,以用于食品工业的面粉搅拌操作。该卧式混合机具有的传动系统,采用 V带和齿轮传 动实现搅拌任务。 本文对卧式混合机的基本结构、基本尺寸进行了详细设计,并利用 SOLIDWORKS对混合机结构 进行三维建模, 以便更直观地展现设计思想和进行结构分析; 并对设计零件进行了分析校核, 保证 混合机的可靠运行。 关键词: 卧式;混合机;混合;食品工业 目 录 1 绪论 ..................................................
作者:熊中哲(沃趣科技)
邮箱:orain.xiong@woqutech.com,欢迎交流~
导 语
前文数据库容器化|未来已来我们介绍了基于Kubernetes实现的下一代私有 RDS。其中,调度策略是具体实现时至关重要的一环,它关系到RDS集群的服务质量和部署密度。那么,RDS需要怎样的调度策略呢?本文通过数据库的视角结合Kubernetes的源码,分享一下我的理解。
It was the best of times, it was the worst of times。
—by Dickens.
人类从爬行到直立用了几百万年,但是我们这些码农从Bare Metal到 Container只花了几万分之一的时间。

我有个朋友是维护Mainframe的,他还在使用40年前的系统。
调度策略很重要
看看巨人们在干什么,有助于我们更好的理解这个世界。
Google Borg
先看看Google是如何看待Borg(Kubernetes 的前身)的核心价值。在Google paper <Large-scale cluster management at Google with Borg>中,开篇就定义了 Borg:
It achieves high utilization by combining admission control, efficient task-packing,over-commitment, and machine sharing with process-level performance isolation.
里面还专门介绍了基于CPI (Cycles Per Instruction)测量资源利用率的方式。
AWS RDS
再看看公有云的领头羊, AWS是这样描述其RDS产品的:

不管是Google Borg还是AWS,除了提供更灵活,更开放,更兼容,更安全,可用性更高的系统,都将cost-efficient,high utilization放到了更重要的位置。
提高部署密度,减少硬件的需求量,最终达到降低硬件投入的目标。
同时,
必须满足业务需求。
本文尝试以数据库的视角,从多个角度阐述RDS场景需要怎样的调度策略。
说明:
为了实现更精细化的调度策略,Kubernetes(版本1.7) 调度器提供了17个调度算法。这些算法分为两类Predicate和Priority,通俗的描述是过滤和打分。设计思路大致如下:1.通过过滤算法,从集群中出满足条件的节点;
2.通过打分算法,对过滤出来的节点打分并排名;
3.挑出分数最高的节点,如果有分数相同的,随机挑一个。
本文将基于Kubernetes的实现,结合RDS场景展开,并不会把所有的算法流水账似的写一遍,相关资料很多,有兴趣的同学可以去看文档。具体实现见:① kubernetes/plugin/pkg/scheduler/algorithm/priorities
②kubernetes/plugin/pkg/scheduler/algorithm/predicates
下面进入主题。
调度策略
视角一 : 计算资源调度策略
这里讨论的计算资源仅包含 CPU,Memory:
需要特别说明,毕竟Kubernetes已经支持GPU。
看上去很简单,挑选出一个满足资源要求的节点即可,但是考虑到整合密度和数据库的业务特点并不简单,我们还需要考虑到以下几点:
峰值和均值:数据库的负载随着业务、时间、周期不断变化,到底是基于峰值调度还是均值调度呢?这是一个有关部署密度的问题,最好的办法就像Linux里面限定资源的方式,让我们设置Soft Limit 和Hard Limit,以Soft Limit分配资源,同时Hard Limit又能限定使用的最大资源。Kubernetes也是这么做的,它会通过 Request 和 Limit 两个阈值来进行管理容器的资源使用。
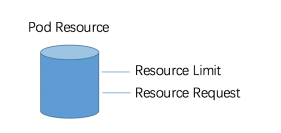
Pod是Kubernetes的调度单位
Requst作为Pod初始分配值,Limit 限定了Pod能使用的最大值。分配时采用Requst值进行调度,这里有个假设:
同一节点上运行的容器不会同时达到 Limit 阈值
有效的实现了计算资源利用率的high utilization,非常适合数据库开发或测试场景。
如果假设不成立,
当某节点运行的所有容器同时接近Limit,并有将节点资源用完的趋势或者事实(在运行的过程中,调度器会定期收集所有节点的资源使用情况,“搜集”用词不太准确,但便于理解),创建 Pod的请求也不会再调度到该节点。

以内存为例, 当Pod的请求超出Node可以提供的内存, 会以异常的方式告知调度器, 内存资源不足
同时,基于优先级,部分容器将会被驱逐到其他节点(例如通过重启 Pod的方式),所以并不适合生产环境。
资源的平衡:对于长期运行的集群,在满足资源的同时还要考虑到集群中各节点资源分配的平衡性。
类似Linux Buddy System,仅仅分配进程需要的内存是不够的,还要保障操作系统内存的连续性。
举个例子,RDS集群有两个节点,用户向RDS申请 2颗CPU和4GB内存 以创建 MySQL实例,两节点资源使用情况如下:
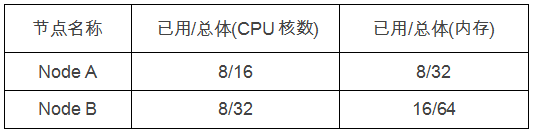
在资源同时满足的情况下,调度会通过两个公式对节点打分。
基于已使用资源比率(Balanced Resource)打分,实现如下:
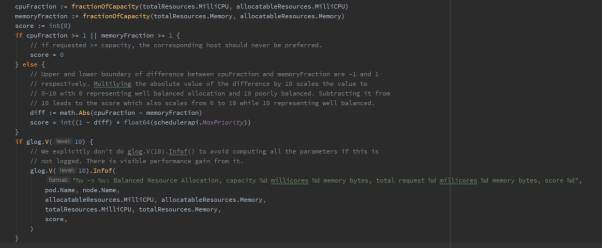
将节点资源输入公式,可简化成:
NodeA 分数 = int(1-math.Abs(8/16 - 8/32)) * float64(10) = 30/4
NodeB 分数 = int(1-math.Abs(8/32 - 16/64)) * float64(10) = 10
基于该算法Node B的分数更高。
再通过未使用资源(calculateUnused)持续打分。

该算法可简化成:
cpu((capacity - sum(requested)) * 10 / capacity) + memory((capacity - sum(requested)) * 10 / capacity) / 2
有兴趣的同学可以算一下,不再赘述。
数据库会被调度到综合打分最高的节点。
视角二 : 存储资源调度策略
存储资源是有状态服务中至关重要的一环,也让有状态服务的实现难度远超无状态服务。
除了满足请求数据库的存储资源的容量要求,调度策略必须要能够识别底层的存储架构和存储负载,在提供存储资源的同时,满足数据库的业务需求(比如数据零丢失和高可用)。
从2017年年初开始,基于分布式存储技术,我们的RDS已经实现了计算和存储分离的架构。
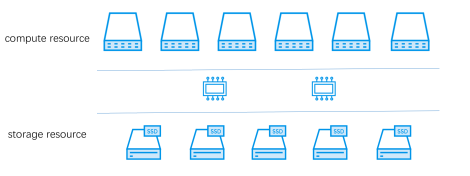
计算存储分离
在实现数据库的数据零丢失,高可用的同时,架构变得更通用,更简单。但对企业级用户,还远远不够,cost-efficient 是考量产品成熟度的重要因素。
所以从一开始,我们就以3种维度的存储QoS来思考这个问题:
从功能角度 :存储资源分成两大类
distribution,基于分布式存储技术实现,对 Flash 设备做了专门的 优化,提供数据冗余和弹性扩容功能;
local,使用计算节点本地存储。
对于生产环境,我们会申请distribution资源。而那些不太重要的或者临时性的,譬如有的客户需要经常生成临时性的克隆库进行测试,或者扩展临时备库以应对突发的业务高峰,我们会申请local资源。
从性能角度:我们又将distribution分成了两类high和medium,以应业务不同的IOPS,Through put,Latency需求。
IO密集型业务,我们会分配high类型。对于计算密集型或者重要值很高的备库,我们会分配medium类型。
从数据库角度:比如, 不同的数据库物理卷的挂载参数也不同;
如果调度器能够实现, 将极大的提高存储资源的cost-efficient。
这些特性带有明显的数据库业务特性,原生的Kubernetes调度器并不支持。但是,我们通过二次开发,Out of Cluster的方式实现了外置的Kubernetes storage provisoner,并通过自定义的参数和代码实现和调度器的交互。

Kubernetes会使用我们提供的storage provisoner创建存储资源.
这样Kubernetes的调度器就可以基于RDS的业务需求,感知底层存储架构,提供满足业务需求的调度服务。
除去需要的容量信息,需要传递给调度器如下信息(就像请CPU,Memory资源一样):
volume.beta.kubernetes.io/mount-options: sync
volume.orain.com/storage-type: "distribution"
volume.orain.com/storage-qos: "high"
volume.orain.com/dc-id: "278"
通过这四个参数将会告知。
从功能角度:volume.orain.com/storage-type: "distribution", 使用 distribution 类型存储资源。
从性能角度:volume.orain.com/storage-qos: "high", 从高性能存储池获取 Volume
从数据库角度:volume.beta.kubernetes.io/mount-options: sync, 使用特定 mount 参数
volume.orain.com/dc-id: "278", 使用编号为278的 Volume
视角三 : 关系型数据库
关系型数据库是有状态服务,但要求更加复杂。比如我们提供了MySQL的Read Write Cluster(读写分离集群) 和Sharding Cluster (分库分表集群),每个数据库实例都有自己的角色。调度器必须感知集群角色以实现业务特点:
比如, 基于数据库角色, 我们有如下调度需求:
ReadWrite Cluster的Master和Slave不能调度到同一节点 Master的多个Slave不能调度到同一节点 Sharding Cluster的每个分片不能调度到同一节点 某些备份任务须调度到指定Slave所在的节点 …..带有明显的业务(RDS)特点,原生Kuberentes的调度策略并不能识别这些角色和关系。
与此同时,容器的运行状态和RDS集群还在动态变化:
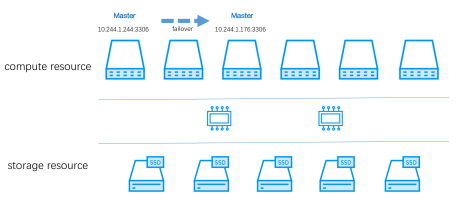
因 Failover迁移到其他节点
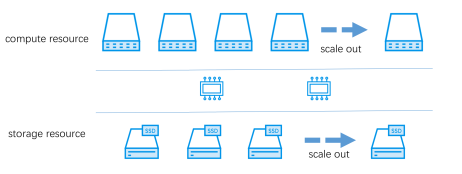
RDS集群 Scale Out
以上具体的问题抽象成:
亲和性(Affinity), 反亲和性(Anti-Affinity)和分布度(Spread Width)
再通过我们的二次开发,将数据库的角色和业务流程集成到调度器中,以满足全部需求。
亲和性(Affinity)调度需求4可以归纳到这里
需求4 : 某些备份任务须调度到指定 Slave 所在的节点
在所有节点中找到指定 Slave 所在节点, 以确定待调度备份任务调度到哪个节点. 该需求必须满足, 不然备份任务无法成功.
建立已运行数据库和节点的关系,在通过Affinity和Anti-Affinity公式对所有节点打分,以此决定待调度数据库是否要调度到该节点。
查找该节点所有数据库实例:

确定该节点是否有指定 Slave:
反亲和性(Anti-Affinity)需求1 : ReadWrite Cluster的 Master和 Slave不能调度到同一节点
以待调度数据库的角色为输入,建立已运行数据库和节点的关系,再通过 Anti-Affinity 公式对所有节点打分,以此决定待调度数据库是否要调度到该节点。
以需求1为例,统计集群成员的分布情况,该节点上同一数据库集群的成员越多,分数越低。
反亲和性(Anti-Affinity)公式
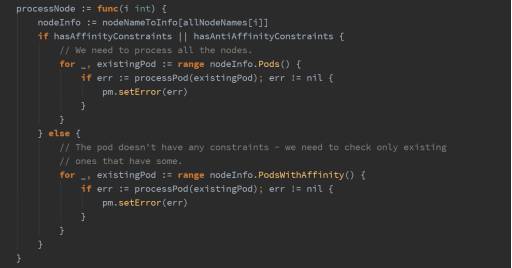
对所有节点打分
分布度(Spread Width)有种更时髦的叫法散射度(scatter width)
需求2,3可以归纳到这里。
以需求2为例, 统计集群成员的分布情况, 该节点上同一数据库集群的成员越多, 分数越低。
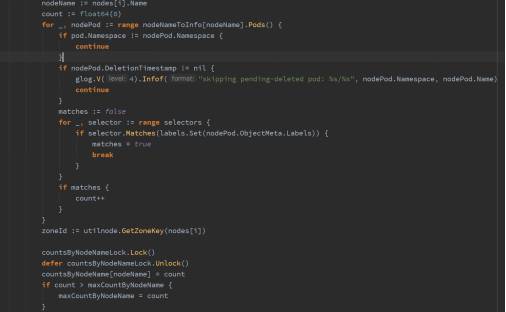
然后对所有节点打分,公式如下:
float64(schedulerapi.MaxPriority) * ((maxCountByNodeName -countsByNodeName[node.Name]) / maxCountByNodeName)
需要特别说明的是, 在RDS进行调度时:
需求1,4必须满足; 需求2,3尽量满足既可以。必须和尽量也需要作为调度参数,让调度器知晓。
结 语
本文仅以RDS的视角,从三个层级讲述了对调度器的要求。
真实的世界会更加复杂,比如针对Read Write Cluster,Slave必须等待Master创建完毕,而Sharding Cluster,所有分片可以并发创建……
在设计产品和完成编码的过程中,踩坑无数。不能否认的是,站在巨人的肩膀上可以让我们看的更远。不知道Ending怎么写, 就这样吧。
BTW,如果你对我们正在做的事情感兴趣,投简历我吧:orain.xiong@gmail.com




知数堂
rds信号发生器广泛用于DVD家庭影院系统,移动便携式收音机,车载DVD音响系统,汽车收音机,GPS定位导航接收机等设备的RDS(RBDS)作用的测试和检验。
1、RDS,RBDS数据的编写是基于windows可视化图形操作界面,非常方便工程师们按照自己的意愿输入相关测试信息。
2、RF的频率范围从70MHz 到110MHz频率调节步进为100KHz或10KHz。
3、RF输出信号电平强度0dB?到100dB?(加强功率型输出为126dB?), 电平调节步进为1dB?。
4、面板设置的快捷开关"RF2"可方便从低端到高端改变RF载波频率,满足RDS接受机的EON及AF作用的全波段内检验测试(无需再外接任何信号发生器)。
5、面板配置的RDS/RBDS图案开关,可触发调出工程师自己定义的RDS图案类型。
6、方便的RS232编程下载模式。
7、设计上吸收了松下VP8194B和利达3217标准频率和标准输出电平的优点,同时容入了嵌入式适时操作系统,将枯燥的RDS图案数据编程在windows界面下做到可视图形化,傻瓜化添写,极大的方便了使用工程师对仪器的使用。
8、RDS/RBDS基带信号输出1.5Vp~p;音频+RDS/RBDS基带信号输出3.0Vp~p。
9、20组AF频率列表,几乎含盖接收机低中高各个频点.
RDS系列螺带式混合机相关推荐
- 相关百科
- 相关知识
- 相关专栏
- REGENERATION
- RHP 7044X2DB轴承
- RJW7101
- ROYALSHOW御秀
- RS107减速机
- RSRDS431
- RT-5000胶带切割机
- RV971A振动传感器
- RWD60西门子控制器
- RX27水泥电阻
- RX77减速机
- RYG1型金属氧化膜电阻器
- Raycop
- Raymond grinder
- Redmi 智能电视 X 2022 款
- Roomba扫地机器人
- 一拖一变频柜电气原理图(三晶VM1000B系列)
- 影响我国公路桥梁板式橡胶支座质量的因素及应对措施
- 张力式电子围栏周界防范报警系统设计原理及应用现状
- 医药工业空调带转轮热回收装置的工程设计和节能分析
- 云南省高寒山区发展被动式太阳能建筑的区域优势
- 永嘉碧桂园翡翠郡附着式升降脚手架安全专项施工方案
- 在这里卡住 防止螺栓连接松弛的成对的楔形锁紧盘
- 变频控制多联式空调系统
- 异构分布式防火墙与入侵检测联动构架的通信机制
- 环境设计专业卓越工程师培养模式探析
- 以电动葫芦为起升机构的简易强制式升降机钢丝绳检验
- 整体式抛填侧向爆破施工工艺在爆破挤淤施工中的应用
- 多乐士竹炭森呼吸系列墙面漆
- 以色列ELI自清洗网式过滤器和浅层介质过滤器简介
- 整体式先张法预应力混凝土复合圆管涵洞的结构及安装
- 双螺杆真空泵转子的接触线及动平衡特性
最新词条
安徽省政采项目管理咨询有限公司
数字景枫科技发展(南京)有限公司
怀化市人民政府电子政务管理办公室
河北省高速公路京德临时筹建处
中石化华东石油工程有限公司工程技术分公司
手持无线POS机
广东合正采购招标有限公司
上海城建信息科技有限公司
甘肃鑫禾国际招标有限公司
烧结金属材料
齿轮计量泵
广州采阳招标代理有限公司河源分公司
高铝碳化硅砖
博洛尼智能科技(青岛)有限公司
烧结刚玉砖
深圳市东海国际招标有限公司
搭建香蕉育苗大棚
SF计量单位
福建省中亿通招标咨询有限公司
泛海三江
威海鼠尾草
广东国咨招标有限公司
Excel 数据处理与分析应用大全
甘肃中泰博瑞工程项目管理咨询有限公司
山东创盈项目管理有限公司
当代建筑大师
拆边机
广西北缆电缆有限公司
大山槟榔
上海地铁维护保障有限公司通号分公司
舌花雏菊
甘肃中维国际招标有限公司
华润燃气(上海)有限公司
湖北鑫宇阳光工程咨询有限公司
GB8163标准无缝钢管
中国石油炼化工程建设项目部
韶关市优采招标代理有限公司
莎草目
建设部关于开展城市规划动态监测工作的通知
电梯平层准确度
广州利好来电气有限公司
苏州弘创招投标代理有限公司